Import Tool
Submitting an Import job through the Import Tool allows you to use the powerful mapping capabilities of DExTr to import data into ONEcount. Import Jobs are scheduled by the system and run every hour. Jobs run in parallel and can take from a few minutes to several hours to complete. You can enter an e-mail address into your job. If you do, an e-mail will be sent to the e-mail address when your job completes, including relevant information about errors, problems with the job, etc.
To start, choose Import/Export Tool under Data Management on the main menu:
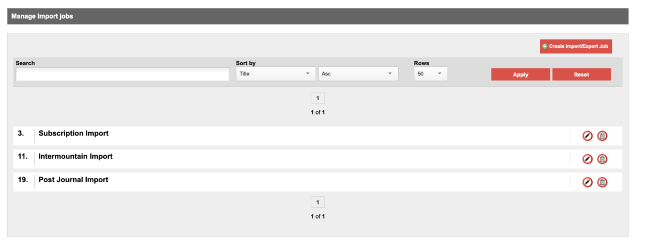
You will see a list of import jobs that are already in the system. Click Create New Import/Export job in the upper-right corner to create a new import job:
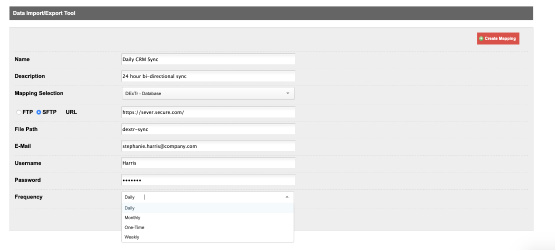
Now you'll create your import job. First, give the job a name and a brief description.
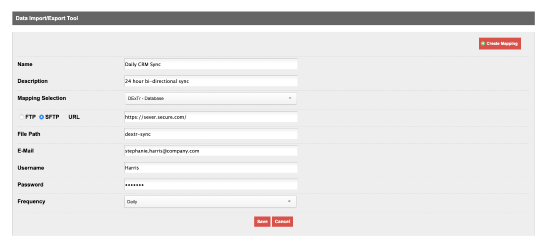
Next, choose which DExTr mapping you will apply to this import. These are the mappings you created in the DExTr screen.
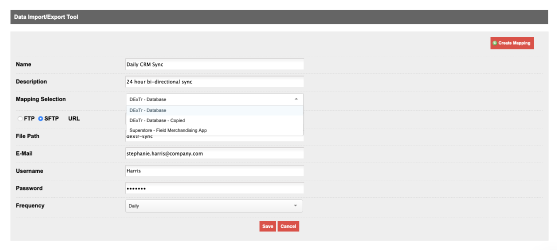
Now choose whether the file should be accessed via FTP, SFTP, or URL. We recommend using SFTP or an HTTPS URL, since most imports involve some sort of PII. You will need to enter the full file path to your file, including the file name.
For example, if you are importing a file called CRM-data.csv, and your file is on an SFTP site and it is in the /files/outgoing/, then in the File Path field you would enter: /files/outgoing/CRM-data.csv.
For repeat imports, some customers use a naming convention with a date place-holder in it. The macro is identified by a pair of %% markers on each end. It's definition is:
YYYY – four-digit year
YY – two-digit year
MM – two-digit month
DD – two-digit date
Using this placeholder, you can specify files such as the following:
file-%%MMYY%%.csv or file-%%MMDDYYYY%%.csv
Please note that when using a date placeholder, ONEcount will only import a file if the date is today's date.
When using a dated naming convention, ONEcount will import files only with a matching date. In other words, if the file name is file-12252019.csv, ONEcount will only import that file on December 25, 2019. On the other hand, if the file name is file-%%MMYY%%.csv, it will import a file named file-1219.csv every day in December 2019.
After the file name, enter the e-mail address that you would like to receive a summary of the import process. You can enter a comma-separated list of addresses.
Next enter the FTP/SFTP/URL login credentials required by the remote system. ONEcount will use these credentials to fetch your file and import it.
Finally, choose the frequency for this import. Available options are Daily, Monthly, One-Time or Weekly.
When you are done, hit Save and your Import Job will be saved into the system. It will run the next time ONEcount scans your queue for jobs, and you'll receive an e-mail notifying you when the job is completed.
Import Job Status
When you save a job, the web UI sets it to "Active". We then have an import scheduler that pre-flights the job and moves it into the active queue. The scheduler checks to see if the SFTP credentials work, if the file is there, if the mapping is correct, etc. If the scheduler finds a problem with the file, it will update the last run time and set it to "processed." If there is nothing wrong with the file and it is ready to go, it sets the status to "Queued". It can take anywhere from a few seconds to an hour for the scheduler to get to the job and act on it. The scheduler is what sent you the e-mail complaining about the missing headers.
Once the job is queued by the scheduler, the import processor starts running the import, it changes the status to "Processing." When the import processor is done, it changes the status to "processed."
You can queue the job as many times as you want, once the import processor starts running it, the job is locked until it either finishes or until someone kills it.
The processor can take a long time to process a file--we get files of 10 or 15 million records or more that can take hours to process. So while the processor is running, it updates a database with a timestamp for that specific job. It's like a heartbeat. This just lets us know the job is a live and still running properly. We then have a monitor running that checks this database and if it doesn't see a heartbeat for an hour, it assumes the job is dead. At that point, it will kill the import job and reset its status to Active so it can run again. It then dumps a copy of the import job logs and sends the team an e-mail that the job was reset.
Jobs can hang for a number of reasons. Most of the time it's transient, one of the servers it is talking to has a problem... there's various reasons. It doesn't happen too frequently, and when it does, the job processes correctly the second time and the customer doesn't notice. This doesn't happen if a job takes a long time, only if it stops processing for some reason.
Note on Source Code Handling in Import
For import transaction types, the source code is determined as follows:
- Mapped Source Code in DExTr Mapper
- If a source code is mapped in the DExTr mapper, the system will import and assign the source code based on that mapping.
- No Mapping, but Source Code Field Present
- If no source code is mapped, but the source code field is included in the mapper:
- The import job will read the source code from the file.
- If the source code does not already exist in the system, a new source code will be created and assigned to the record.
- If no source code is mapped, but the source code field is included in the mapper:
- Null or Empty Source Code in File
- If the source code field in the import file is null or empty:
- The system will assign the default source code to the transaction which is assigned on Import Tool.
- If the source code field in the import file is null or empty:
Note on Promo Code Handling in Import
For import transaction types, the promo code is determined as follows:
- Mapped Promo Code in DExTr Mapper
- If a promo code is mapped in the DExTr mapper, the system will import and assign the promo code based on that mapping.
- No Mapping, but Promo Code Field Present
- If no promo code is mapped, but the promo code field is included in the mapper:
- The import job will read the promo code from the file.
- If the promo code does not already exist in the system, a new promo code will be created and assigned to the record.
- If no promo code is mapped, but the promo code field is included in the mapper:
- Null or Empty Promo Code in File
- If the promo code field in the import file is null or empty than that transaction will be imported with empty promo code.